Исполнитель, песня
Спектр
Спектр, при пропускании сигнала через ФВЧ 2-го порядка с характеристикой Баттервота fс=3500 Гц
В многополосных акустических системах каждый из динамиков подлючается к выходу усилителя через фильтр ВЧ, НЧ, либо полосовой. И естественно, что на каждый динамик поступает только часть всей мощности, отдаваемой усилителем. То какая это часть, зависит как от свойств самого фильтра (частоты среза и порядка), так и от свойств музыкального сигнала, воспроизводимого усилителем. А именно - от его спектра. В настоящее время принят ряд стандартов, "узаконивающих" определенное спектральное распределение музыки, например, DIN 45 573, IEC 268-5. Однако есть подозрения, что эти стандарты несколько устарели, и спектр современной музыки оказывается более насыщен верхними частотами, чем предполагается. В любом случае, дополнительное исследование на эту тему никому не помешает.
Перед данным исследованием ставились следующие цели:
Все, что здесь представлено, получено путем "компьютерного эксперимента". Тем не менее, результаты достоверны, так как для работы использовались реально (и качественно!) работающие программы, а в качестве звукового материала - реаьльные музыкальные записи на компакт-дисках (аудио, обязательно не mp3 - вероятность аудиозаписи, полученной конвертированием из этого формата специально проверялась). По возможности использовались лицензионные диски. Реальные аналоговые измерения "в железе" дадут не сильно отличающиеся значения (а если учесть, что наиболее вероятным источником фонограмм являются именно CD... ).
Для исследования спектров были выбраны 8 композиций различных жанров (рок, диско, легкая музыка 60-х, современное "тыц-тыц"). Треки сграблены с CD и исследованы в программе Adobe Audition. Выбор песен основывался на разнообразии жанров и "персональных особенностях" - например у группы Supermax много низких; а "тыц-тыц" я выбирал по максимальному содержанию высоких частот (спектроанализатором WinAmp'a при предварительном прослушивании). Кроме того, учитывалось качество источника сигнала. Количество песен явно недостаточно для полноценной статистики, но тем не менее этого вполне хватит для тех выводов, которые будут сделаны. Для ускорения работы, исходные стереофайлы были конвертированы в моно и в таком виде сохранены для дальнейшей работы.
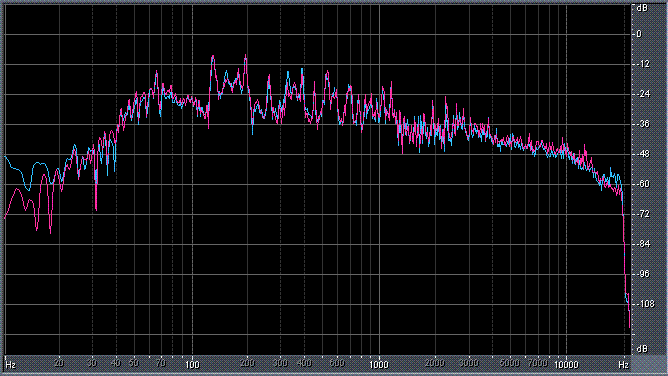
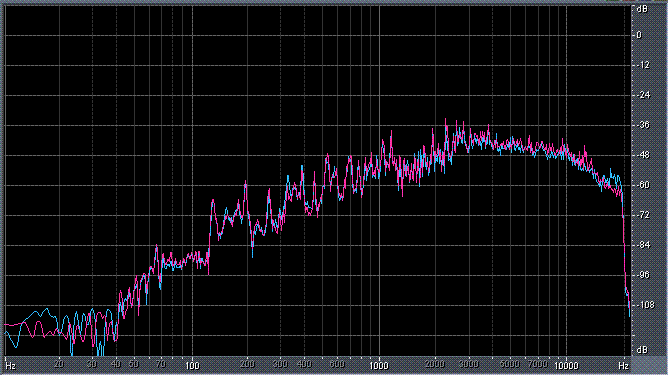
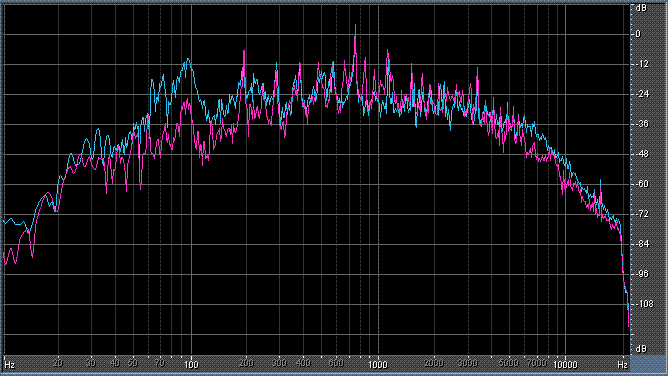
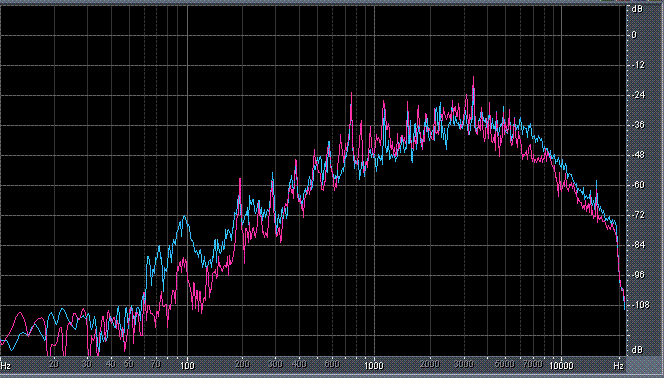
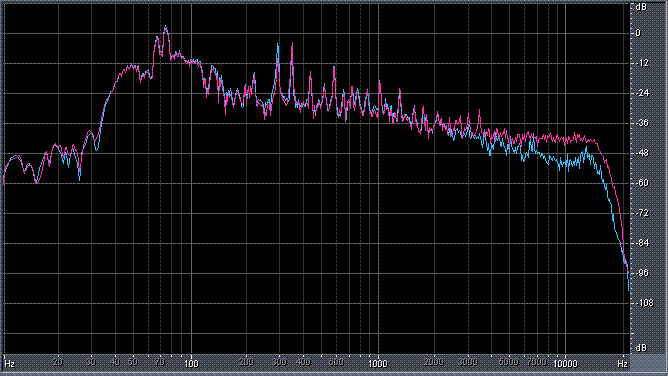
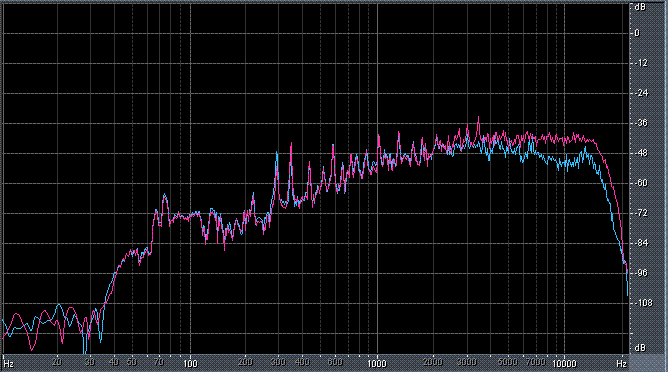
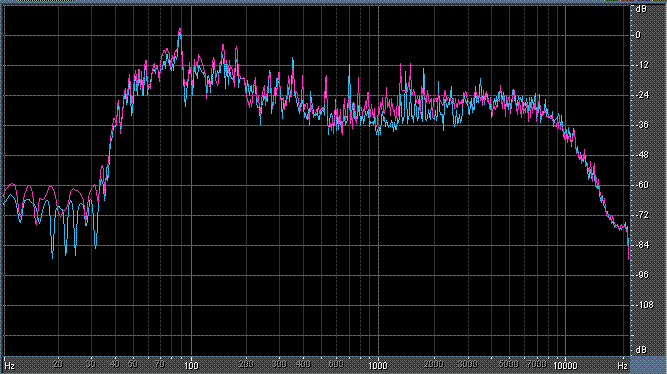
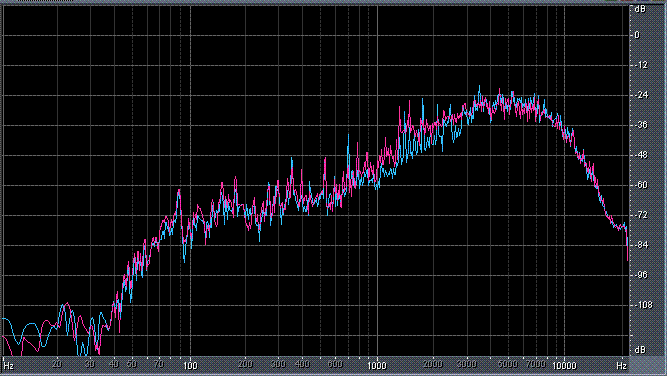
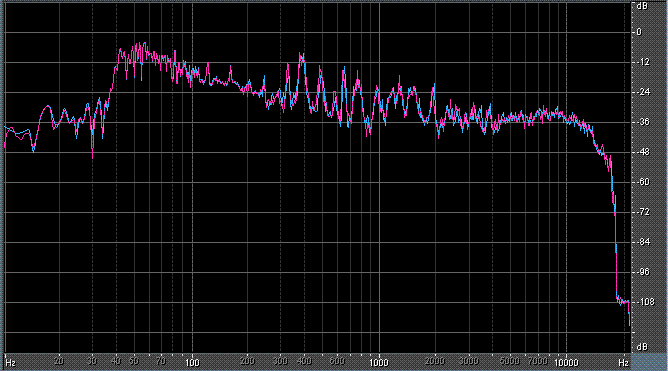
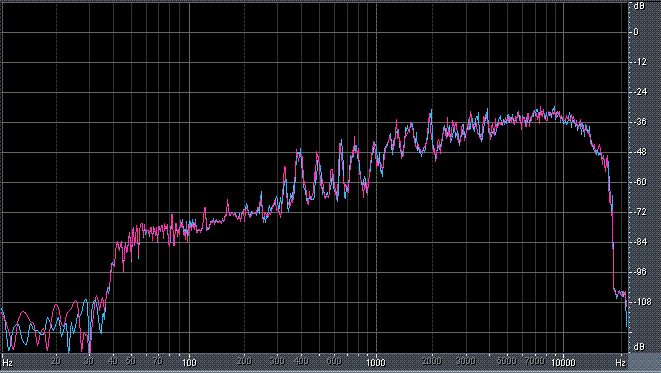
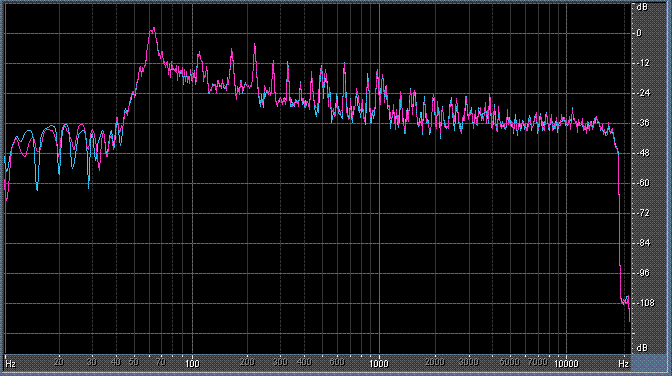
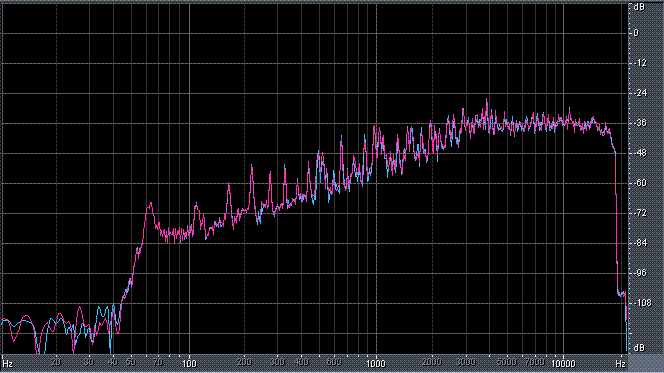
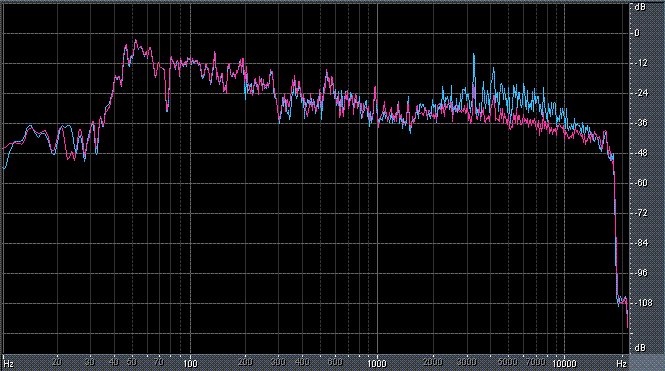
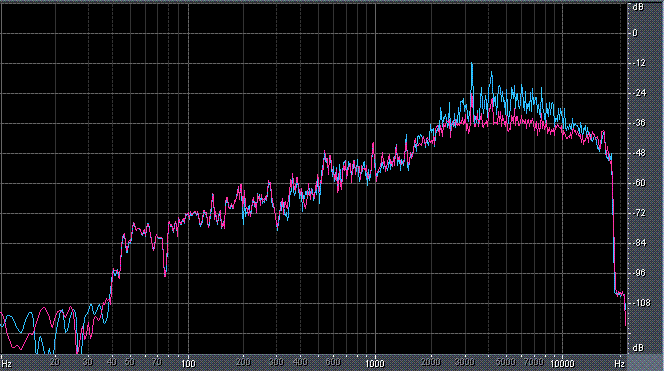
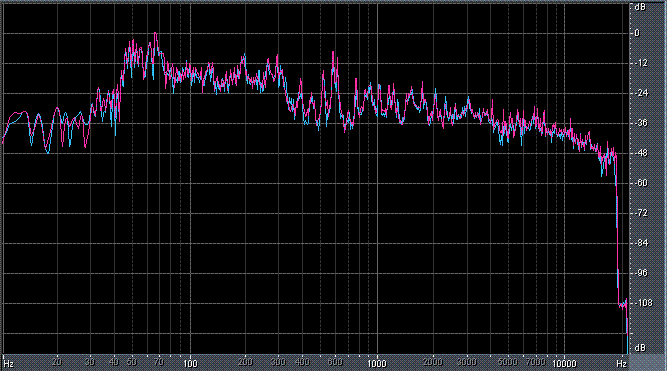
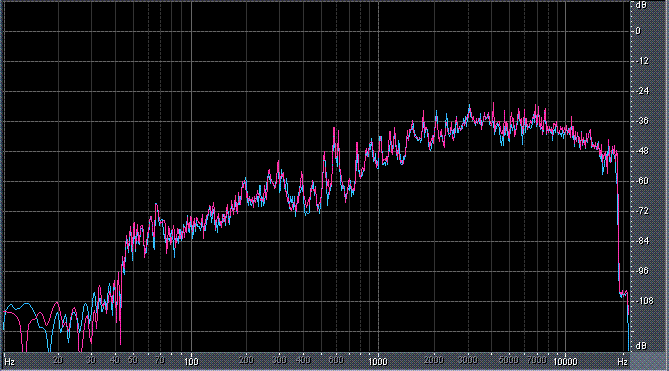
Итак, былы измерены (и построены) усредненные по всей песне целиком спектры. После этого звуковой файл обрабатывался фильтром ВЧ 2-го порядка (аппроксимация по Баттервоту) с частотой среза fс = 3,5 кГц. И снова измерялся его спектр. Результаты представлены в таблице (клик по картинке открывает ее в новом окне). Розовая и голубая кривые соответствуют правому и левому каналам.
Хорошо видно, что кривой DIN распределения энергии спектра наиболее соответствует Paul Anka с песней Diana (по характеру звучания, манере исполнения и репертуару он близкок с группой Platers). У остальных спектры ближе к розовому шуму, да и то, низкие и высокие зачастую оказываются "приподнятыми". После фильтра с частотой среза fс = 3,5 кГц у группы Supermax спад АЧХ начинается на частоте 1 кГц, а выше АЧХ практически горизонтальна. То есть, диапазон частот, который приходится на динамик получается гораздо шире (реально от 1 кГц до 20 кГц, а не от 3,5 кГц).
Исполнитель, песня |
Спектр |
Спектр, при пропускании сигнала через ФВЧ 2-го порядка с характеристикой Баттервота fс=3500 Гц |
| ELO, There Is The News | |
|
| Paul Anka, Diana | |
|
| Supermax, Camillo | |
|
| Deep Purple, Highway Star | |
|
| E-Type, Olympia | |
|
| Benassy Bros feat Dhany, Hit My Heart | |
|
| VS, Call U Sexy | |
|
| Fabrizio Faniello, I'm in Love | |
|
Теперь посчитаем, что там делается в спектрах, приведенных выше. С помощью Adobe Audition определяем статистические параметры исходных сигналов (в звуковых файлах). И параметры тех же сигналов, но после фильтрации. Вот результаты:
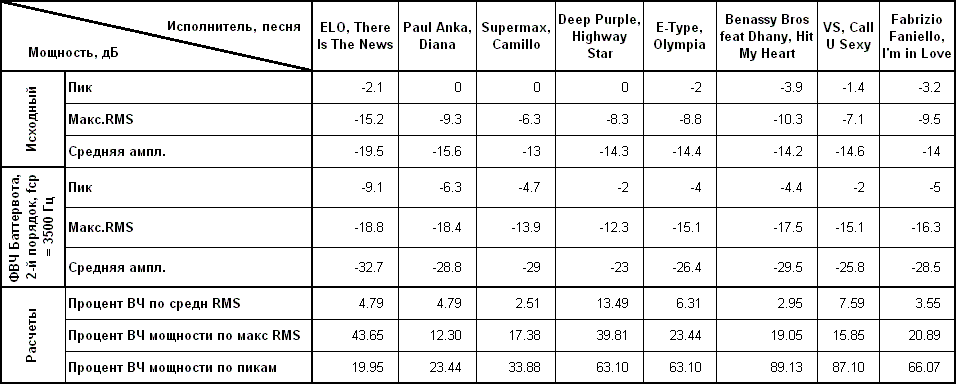
Примечания:
Вообще-то пик - это такая штука, что на нее можно не обращать внимания. Это очень кратковременный, следовательно высокочастотный всплеск. Поэтому применения фильтра мало влияет на пиковую мощность. В дальнейшем эту мощность не рассматриваем. Легко увидеть, что значения для разных песен сильно различаются. Обработаем результаты статистически и выразим в процентах:

Ну что можно сказать? Разброс +/- 50% от среднего значения даже на такой маленькой выборке говорит по крайней мере о двух вещах: